
What and how it can be used:
The Guardrail component acts as a safety and quality control layer that validates, monitors, and filters inputs and outputs to ensure AI agent behavior remains safe, appropriate, and aligned with policies. It detects and prevents harmful content, policy violations, jailbreak attempts, PII leaks, hallucinations, and other undesired behaviors before they reach users or external systems.
When/how the component should be used:
- When compliance, safety, or trust is critical.
- When outputs can trigger real-world actions.
- Used to detect sensitive information, enforce content policies, validate outputs, and prevent unsafe behaviors before they cause problems.
- Used to validate output quality and accuracy.
- Implement guardrails using middleware to intercept execution at strategic points – before the agent starts, after it completes, or around model and tool calls.
- Use rule-based logic like regex patterns, keyword matching, or explicit checks. Fast, predictable, and cost-effective, but may miss nuanced violations.
Connections with other components:
- Chat Output
- Text Input
- Text Output
- Agent Core
- API Request
- Directory
- News Search
- RSS Reader
- SQL Database
- Web Search
- Language Model
- Batch Run
- LLM Router
- Parser
- Python Interpreter
- Save File
- Smart Function
- Split Text
- Structured Output
- Type Convert
- Listen
- Smart Router
- Calculator
- Anonymization
- Human-in-the-loop
- Bing Search API
- Google Search API
- ChromaDB
Configurable settings:
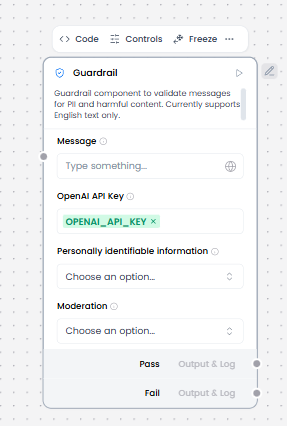
- Message (From component or write the message)
- OpenAI API Key
- Moderation ( Choose option from List select)
- Personally Identifiable Information ( Choose option from List select)
Default settings:
- Message (From component or write the message)
- OpenAI API Key
- Moderation ( Choose option from List select)
- Personally Identifiable Information ( Choose option from List select)
Control Section:
- Message
- Personally Identifiable Information
- OpenAI API Key
- Moderation
- Output Mode
Default values:
- Output Mode = Both Outputs
Desired Behaviour:
- Detect/redact PII, Flag harmful content, and Configurable sensitivity.
- Prevent unsafe, non-compliant, or undesired behavior while still allowing helpful responses when possible.